



Paul Jacobs
SRA International, Arlington, Virginia, USA
The proliferation of on-line text motivates most current work
in text interpretation. Although massive volumes of information
are available at low cost in free text form, people cannot read and digest this
information any faster than before; in fact, for the most part they can digest
even less. Often, being able to make efficient use of information from text
requires that the information be put in some sort of structured format, for
example, in a relational database, or systematically indexed and linked. Currently, extracting the information required for a
useful database or index is usually an expensive manual process; hence on-line
text creates a need for automatic text processing methods to extract the
information automatically (Figure  ).
).

Figure: The problem of information extraction from
text.
Current methods and systems can digest and analyze significant volumes of
text at rates of a few thousand words per minute. Using text skimming,
often driven by finite-state recognizers (discussed in chapters 3 and 11 of this
volume), current methods generally start by identifying key artifacts in the
text, such as proper names, dates, times, and locations, and then use a combination of
linguistic constraints and domain knowledge to
identify the important content of each relevant text. For example, in news
stories about joint ventures, a system can usually identify
joint venture partners by locating names of companies, finding linguistic
relations between company names and words that describe business tie-ups, and
using certain domain knowledge, such as understanding that ventures generally
involve at least two partners and result in the formation of a new company.
Other applications are illustrated in [CCC92,M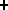 95].
Although there has been independent work in this area
95].
Although there has been independent work in this area
and there are a number of systems in commercial use, much of the recent progress in this area has come from U.S. government-sponsored programs and evaluation conferences, including the TIPSTER Text Program and the MUC and TREC evaluations described in chapter 13. In information extraction from text, the TIPSTER program, for example, fostered the development of systems that could extract many important details from news stories in English and Japanese. The scope of this task was much broader than in any previous project.
The current state of the art has produced rapid advances in the robustness and applicability of these methods. However, current systems are limited because they invariably rely, at least to some degree, on domain knowledge or other specialized models, which still demands time and effort (usually several person-months, even in limited domains). These problems are tempered somewhat by the availability of on-line resources, such as lexicons, corpora, lists of companies, gazetteers, and so forth, but the issue of how to develop a technology base that applies to many problems is still the major challenge.
In recent years, technology has progressed quite rapidly, from systems that could accurately process text in only very limited domains (for example, engine service reports) to programs that can perform useful information extraction from a very broad range of texts (for example, business news). The two main forces behind these advances are: (1) the development of robust text processing architectures, including finite state approximation and other shallow but effective sentence processing methods, and (2) the emergence of weak heuristic and statistical methods that help to overcome knowledge acquisition problems by making use of corpus and training data.
Finite-state approximation [JKR 93,Per90]
is a key element of current text interpretation methods. Finite-state
recognizers generally admit a broader range of possible sentences than most
parsers based on context-free grammars, and
usually apply syntactic constraints in a weaker fashion. Although this means
that finite-state recognizers will sometimes treat sentences as grammatical when
they are not, the usual effect is that the finite state approximation is more
efficient and fault tolerant than a context-free model.
93,Per90]
is a key element of current text interpretation methods. Finite-state
recognizers generally admit a broader range of possible sentences than most
parsers based on context-free grammars, and
usually apply syntactic constraints in a weaker fashion. Although this means
that finite-state recognizers will sometimes treat sentences as grammatical when
they are not, the usual effect is that the finite state approximation is more
efficient and fault tolerant than a context-free model.
The success of finite-state and other shallow recognizers, however, depends on the ability to express enough word knowledge and domain knowledge to control interpretation. While more powerful parsers tend to be controlled mainly by linguistic constraints, finite state recognizers usually depend on lexical constraints to select the best interpretation of an input. In limited domains, these constraints are part of the domain model; for example, when the phrase unidentified assailant appears in a sentence with terrorist attack, it is quite likely that the assailant is the perpetrator of the attack.
In broader domains, successful interpretation using shallow sentence processing requires lexical data rather than domain knowledge. Such data can often be obtained from a corpus using statistical methods [CGHH91]. These statistical models have been of only limited help so far in information extraction systems, but they show promise for continuing to improve the coverage and accuracy of information extraction in the future.
Much of the key information in interpreting texts in these applications comes
not from sentences but from larger discourse units, such as
paragraphs and even complete documents. Interpreting words and phrases in the
context of a complete discourse, and identifying the discourse structure of
extended texts, are important components of text interpretation. At present,
discourse models rely mostly on domain knowledge [IAA 91].
Like the problem of controlling sentence parsing, obtaining more
general discourse processing capabilities seems to depend on the
ability to use discourse knowledge acquired from examples in
place of detailed hand-crafted domain models.
91].
Like the problem of controlling sentence parsing, obtaining more
general discourse processing capabilities seems to depend on the
ability to use discourse knowledge acquired from examples in
place of detailed hand-crafted domain models.
We can expect that the future of information extraction will bring broader and more complete text interpretation capabilities; this will help systems to categorize, index, summarize, and generalize from texts from information sources such as newspapers and reference materials. Such progress depends now on the development of better architectures for handling information beyond the sentence level, and on continued progress in acquiring knowledge from corpus data.